알고리즘은 숫자를 가지고 계산되지만, 이를 위해 사람이 결정하고 입력해줘야 하는 값이 있습니다. 이 중에는 애매한 값을 사람이 입력해줘야 하는 경우도 있습니다. K-means 클러스터링 알고리즘의 군집 개수도 이와 같은데요. 오늘은 K-means 클러스터링 알고리즘의 군집 개수를 정하는 방법에 대해서 알아보겠습니다.
K-Means알고리즘은 대표적인 비지도 학습 알고리즘의 하나입니다. 특징 중 하나는 군집의 갯수를 미리 정해야 한다는 것인데요. 그럼 군집의 개수를 어떻게 정해야 할까요.
군집의 갯수를 정하는 가장 대표적인 방법은 감입니다
이런 감을 업무 용어로 비즈니스 지식이라고 합니다. 도메인 지식이라고도 부르는 이 영역을 필자는 감이라고 부릅니다. 해당 업무를 오래 한 사람은 그동안의 업무 경험과 지식을 가지고 해당 데이터는 이 정도 개수가 적당하지 않을까 하고 말할 수 있습니다. 그리고 이 방법이 사실 제일 좋은 것 같습니다.
하지만 사람들은 감을 싫어합니다
왜 3개인지 4개는 안 되는지에 대해 물어보면 딱히 답할 말이 없습니다. 자신의 일은 감으로 처리하는 게 많지만 뭔가 알고리즘이고 모델이라서 그런지 유달리 이 쪽 영역으로 오면 듣는 사람은 감을 싫어합니다.
갑자기 예전에 애매한 것을 정해주던 애정남이 생각납니다. 사람들은 뭔가를 결정하는 것에 두려움을 갖습니다. 그래서 알고리즘이 필요한 걸 지도 모르겠네요.
군집의 개수를 가이드해 주는 방법이 있습니다
군집 개수를 수학적으로 정하는 방법을 찾아보니 Elbow method(엘보우 메소드)라는 방법이 있습니다. 군집을 추가로 늘려가면서 군집내 변동성이 급감하는 군집 개수를 찾는 것이라고 합니다.
군집내 변동성이 급감했다는 것은 유사한 녀석들끼리 잘 묶였다는 뜻이기 때문인데요. 이것도 하나의 가이드일 뿐 무조건 이 기준으로 정해서는 안 된다고 합니다. 하지만 누군가에게 설명하기 좋은 방법인 건 분명합니다.
Elbow method를 테스트해보기 위해 샘플 데이터를 만들어 보았습니다. 누가 보아도 극명하게 3개의 그룹으로 묶이는 데이터셋입니다.
import numpy as np
import seaborn as sns
x= np.concatenate((np.random.uniform(0.1,0.3,50),
np.random.uniform(0.4,0.7,50),
np.random.uniform(0.9,1,50)), 0)
sns.distplot(x, bins=50)
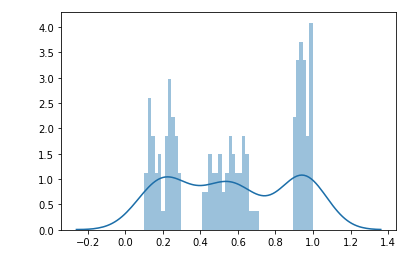
3개의 군집으로 클러스터링을 해 보았습니다. fit를 하고나서 score함수를 이용하면, elbow method에 사용하는 군집의 변동성을 확인하는 지표를 산출할 수 있습니다.
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3)
model.fit(x.reshape(-1,1))
print(model.score(x.reshape(-1,1)))
[결과]: -0.49197957396021536
군집의 개수별로 학습을 하고, score함수를 이용해서 비교해도 됩니다. 하지만, yellow brick이라는 패키지를 이용하면 더 쉽게 Elbow Method를 활용해 볼 수 있습니다. 옐로우 브릭은 머신러닝 시각화를 지원해주는 패키지입니다. ROC 커브를 그릴 때도 유용하게 사용됩니다.
yellow brick이라는 패키지를 이용하면 쉽게 시각화까지 할 수 있습니다. 코드도 어렵지 않습니다.
from yellowbrick.cluster import KElbowVisualizer
model = KMeans()
visualizer = KElbowVisualizer(model, k=(1,10))
visualizer.fit(x.reshape(-1,1))
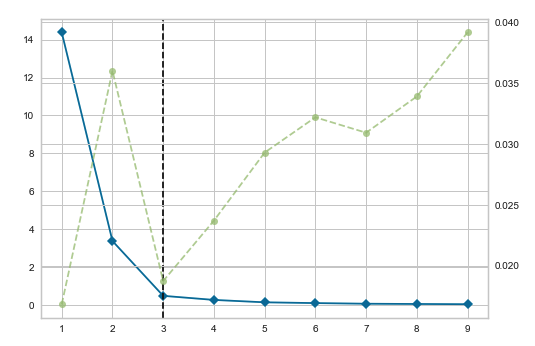
파란선이 그룹의 변동성을 확인하는 지표입니다. 군집의 갯수가개수가 1에서 2로 늘어날 때 변동성이 급감하지만, 군집의 개수가 3개 이후에는 거의 변동성이 없습니다. 3개가 가장 적당한 것을 눈으로 확인할 수 있는데요. 세로 점선으로 최적의 군집 개수도 표시해줍니다.
녹색 점선이 좀 재밌는데, 이것은 군집을 학습할 때 걸린 시간입니다. 군집이 3개일 때 걸리는 시간이 가장 적습니다. 군집이 갯수가개수가 늘어날수록 학습 시간이 오래 걸릴 것 같기는 한데, 군집의 개수가 2개일 때가 3개보다 시간이 더 오래 걸립니다. 자세한 이유는 알 수 없지만, 클러스트링이 잘 될 때 학습 시간도 적게 걸리는 듯하네요.
참고로 싸이킷런 패키지로 계산한 값에 마이너스를 곱해야 옐로 브릭에서 구한 값이 됩니다. 그러니까 두 패키지 값의 부호가 다른데요. 하나는 양수, 다른 하나는 음수입니다.
군집의 개수를 설명하기 애매할 때 확실한 설명 기준이 될 수는 있겠습니다. 3개로 그룹핑한 결과는 아래와 같습니다. 당연하 애기지만, 클러스트링이 잘 되었습니다.
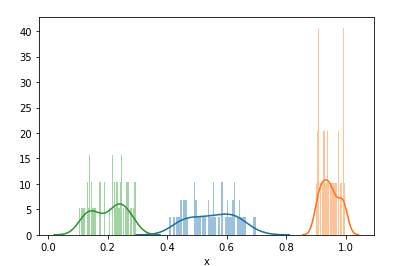
오늘은 이렇게 K-means 클러스터링 군집 개수를 정하는 방법에 대해서 알아보았습니다. 엘보우 메서드를 통해서 군집 내 변동성의 변화로 군집의 개수를 정할 수 있었습니다. 절대적인 기준은 아니지만, 참고 지표로 충분히 사용이 가능하겠습니다.
'데이터 > 데이터 분석' 카테고리의 다른 글
| 파이썬 판다스 groupby 여러개 기준으로 쉽게 요약하는 방법은?! (0) | 2022.04.04 |
|---|---|
| 파이썬 판다스 데이터프레임 출력, 모든 데이터 확인하는 3가지 방법 (0) | 2022.04.03 |
| 파이썬 히트맵 그리는 손쉬운 2가지 방법 (0) | 2022.03.28 |
| 판다스 데이터프레임 칼럼 이름 변경하는 5가지 방법은?! (0) | 2022.03.16 |
| 파이썬 numpy 기초 사용법, ndArray 이용 벡터연산하기! (0) | 2022.02.04 |
| 프롭테크 의미는 무엇이고, 어떤 기업들이 있나요? (0) | 2022.02.03 |
| 내가 정리해 본 분석 과제 발굴 프로세스 및 방법은?! (0) | 2022.02.02 |
| 파이썬 MySQL 연동 및 사용법은?! (0) | 2022.01.29 |



