주가는 시계열 데이터이기 때문에, 딥러닝 모형에 학습해보기 좋은 데이터입니다. LSTM은 언어를 다룰 때 사용되는 모델이지만, 순서가 있는 데이터를 다룰 수 있기 때문에 주가 데이터에도 적용할 수 있습니다. 오늘은 주가 데이터를 LSTM 딥러닝 모형에 학습하는 방법에 대해서 알아보겠습니다.
데이터는 이전 포스팅에서 수집한 삼성전자 주식 데이터를 이용했습니다.
import FinanceDataReader as fdr
ss=fdr.DataReader("005930","2015","2020-07-31")
ss["close_1d"]=ss["Close"].shift(1)
ss["1d_up"]=0
ss.loc[ss["Close"]>ss["close_1d"],"1d_up"]=1
train=ss["2015-01-01":"2018-12-31"]
test=ss["2019-01-01":"2020-7-31"]
1. 데이터 스케일 변환
딥러닝에 데이터를 넣을 때는 0과 1사이의 값으로 변환하는 것이 성능 향상에 도움이 됩니다. 입력 데이터를 변환하기 위해 MinMaxScaler를 사용했습니다.
from sklearn.preprocessing import MinMaxScaler
mms=MinMaxScaler()
train["close_mms"]=mms.fit_transform(train[["Close"]])
2. 데이터 구조 변환
LSTM 알고리즘에 적용하기 위해 데이터를 3차원으로 변경해 줍니다. tf.keras.layers.LSTM의 input은 [batch, timesteps, feature]로 3D tensor를 사용합니다. 종가 데이터를 10일 간격으로 나눈 데이터셋을 만들어 줍니다. 종가상승 하락 여부를 y_train이라는 변수로 만들었습니다.
먼저 train set을 변환합니다.
x_len = 10
import numpy as np
data=list()
for i in range(len(train)-x_len):
data.append(list(train["close_mms"][i: i + x_len].values))
x_train=np.array(data)
print(x_train)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
print(x_train.shape)
y_train= train["1d_up"][x_len:]
print(y_train.shape)
test set도 변환합니다.
test["close_mms"]=mms.fit_transform(test[["Close"]])
test=test.reset_index(drop=False)
import numpy as np
# 31개씩 데이터를 끊는다.
x_test=list()
for i in range(len(test)-x_len):
x_test.append(list(test["close_mms"][i: i + x_len].values))
x_test=np.array(x_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
3. 딥러닝 모델 정의하기
2개의 층으로 이루어진 모델을 만들었습니다. 첫 번째 층은 10개의 LSTM Unit을 정의하고, 두 번째 층은 Unit이 1개인 Dense층을 만들었습니다. 활성화 함수는 sigmod, 손실 함수는 binary_crossentorypy, 옵티마이저는 rmsprop, 메트릭은 accuracy를 사용했습니다.
from keras.models import Sequential
from keras.layers import LSTM, Dropout, Dense, Activation
model = Sequential()
model.add(LSTM(10, input_shape=(10, 1)))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
model.summary()
4. 딥러닝 모델 학습하기
batch size 10, epoch 15로 알고리즘을 학습시킵니다.
modle=model.fit(x_train, y_train,
batch_size=10,
epochs=15)
5. 성능 평가하기
train 데이터와 test 데이터셋의 성능을 확인해 봤습니다. 먼저 train set 성능평가 지표를 확인하였습니다.
pred = model.predict(x_train)
print(pred.shape)
pred=pred.reshape(1,971)[0]
y_pred=np.where(pred>0.5,1,0)
print(pred.shape)
y_1d_up=train[x_len:]["1d_up"].values
from sklearn.metrics import classification_report
print(classification_report(y_1d_up,y_pred))
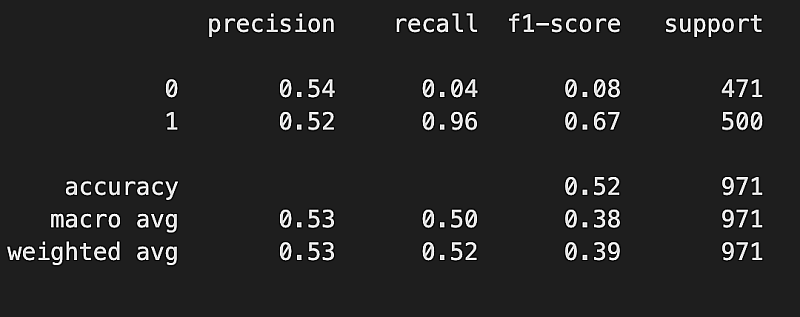
다음 test셋의 성능지표를 확인하였습니다.
pred = model.predict(x_test)
y_test=test[x_len:]["1d_up"].values
y_test_pred=np.where(pred>0.5,1,0)
print(classification_report(y_test,y_test_pred))
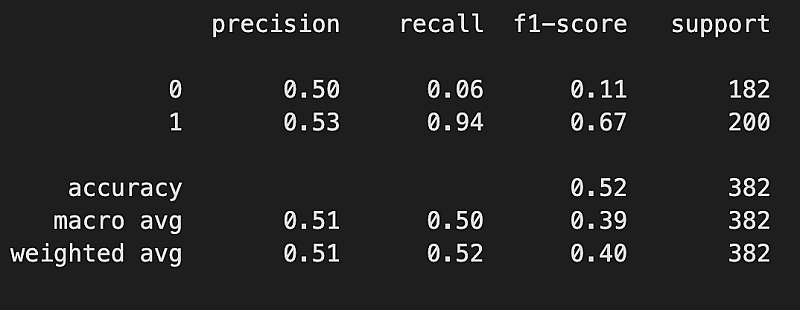
6. 모델 저장하기
최소최대변화 객체를 pickle로 저장하고, LSTM 알고리즘은 save함수를 이용해서 저장합니다.
with open("mms.pkl","wb") as f:
pickle.dump(mms,f)
model.save("keras_lstm_model")
오늘은 이렇게 주가 데이터 LSTM 딥러닝 모형 학습하는 방법에 대해서 알아보았습니다. 다음에는 만든 알고리즘을 이용해서 백테스트를 진행해 보겠습니다.
'파이썬 > 파이썬과 주식투자' 카테고리의 다른 글
| 파이썬 이동평균선 정배열 주식 찾는 법 및 백테스팅 (0) | 2022.11.17 |
|---|---|
| 파이썬 주식 차트 지표 구하는 방법, talib 설치 및 사용법 (0) | 2022.08.01 |
| 주식 데이터 LSTM 알고리즘 백테스트 결과 알아보기 (0) | 2022.07.25 |
| 파이썬 주식 백테스트, backtrader 설치 및 사용 방법 (0) | 2022.07.24 |
| 파이썬 주식 데이터 가공 및 로지스틱 회귀분석 학습하기 (0) | 2022.07.24 |
| 파이썬 주가 이동평균값 구하고 라인 차트 그리기 (0) | 2022.07.24 |
| 주가 데이터 수집 및 차트 그리기 (0) | 2022.07.24 |
| 로보어드바이저 뜻과 개념 알아보기 (0) | 2022.06.29 |



