데이터를 분석하기 위해서는 하나의 값이 아니라, 여러 개의 값을 다뤄야 한다. 이렇게 여러 개의 값을 다루기 위한 자료형은 여러가지가 있다. 그 중 가장 일반적인 것은 '테이블 데이터'라고 해서 행과 열러 이루어진 데이터 구조이다.
dataframe은 이와 같이 행과 열로 이루어진 데이터 구조로 우리가 흔히 아는 DB 테이블과 동일하다. 우리가 이해하기 가장 쉬운 데이터 구조 중에 하나가 아닐까 싶다. 오늘은 파이썬 pandas에서 제공하는 데이터 구조인 dataframe(데이터 프레임)에 대해서 알아보려고 한다.

DataFrame는 numpy의 ndArray를 기반으로 한 행과 열로 이루어진 데이터 구조이다. Series가 1차원 자료구조라면, 이 1차원의 자료구조가 여러 개 모인 2차원 데이터 구조이다. 우리가 흔히 아는 엑셀과 동일한 형태의 자료이다.
python pandas패키지의 dataframe을 사용하기 위해 우선 해당 패키지를 import 한다.
# coding=utf-8
import pandas as pd
data = {
"juso" : ["서울시","인천시","부산시","대구시"],
"name" : ["kim","lee","park","choi"],
"age" : [20, 30 , 40, 50]}
data = pd.DataFrame(data)
# 하나의 칼럼(칼럼명:juso) 보기
data.juso
# 인덱스 1보기
data.loc[1]
# age가 40보다 큰 값만 보기
data[data["age"]>40]
# 열을 추가하기
data["money"]=1000
# 행을 추가하기
data.loc[4]=[60,"광주시","kim",2000]
# transpose
data.T
# reindex하기
data.reindex([4,3,2,1])
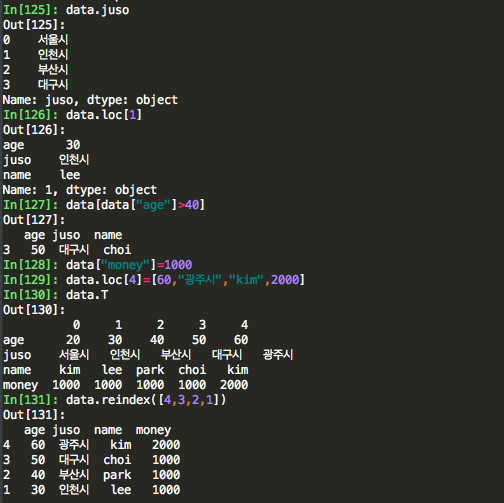
dataframe에서 칼럼을 부를 때는 data["juso"]형식으로 많이 불렀는데, data.juso도 가능하다. "."(dot)을 이용하는게 편리해 보인다. 앞으로는 dot을 이용해서 칼럼을 부르도록 해야겠다.
DataFrame이 어떻게 생겼는지를 알고 싶으면 확인하는 방법이 여러가지 있다. Pycharm이라는 파이썬 IDE(통합개발환경) 프로그램에서도 DataFrame을 엑셀처럼 조회할 수도 있다. 이에 대한 내용은 이전에 자세히 다루었으니 참고하기 바란다.
DataFrame은 numpy처럼 유니버셜 펑션이 가능하다. 그리고 dataframe을 html코드로 추출할 수 있다. html로 표를 그리기가 쉽지 않은데, 매우 유용한 기능인 것 같다. 파이썬에서 작업한 표를 바로 html로 옮길 수 있기 때문이다.
import numpy as np
np.sum(data.age)
# 0부터 2번 인덱스 값 부르기
data[:2]
# 2번 인덱스 행 삭제하기
data.drop(2)
# money 칼럼 지우기
data.drop("money",1)
# html로 보내기
data.to_html()

오늘은 이렇게 파이썬 pandas dataframe이란 무엇이고, 어떻게 사용하는지에 대해서 알아보았다. 우리에게 익숙한 테이블 형태의 데이터 구조로 이해하기도 쉽고, 사용하기도 편리하다. pandas dataframe의 자세한 사용방법은 pandas 튜토리얼을 참조하는 것이 많은 도움이 된다.
pandas dataframe을 사용하다보면 저장할 일이 발생한다. python pandas의 dataframe을 저장하는 여러가지 방법에 대해서 이후에 자세히 다뤄보도록 하겠다.
'파이썬 > 파이썬 기초' 카테고리의 다른 글
| 주피터 노트북 초기 환경설정 BEST3! (0) | 2022.01.27 |
|---|---|
| 주피터 노트북 사용법, interact 모듈 사용하기 (0) | 2022.01.26 |
| 주피터 노트북 단축키 확인하고 쉽게 기억하는 방법은? (0) | 2022.01.26 |
| 파이썬 딕셔너리 합치기, 사전 병합하는 방법은?! (0) | 2022.01.23 |
| 파이썬 리스트와 딕셔너리를 이쁘게 시각화 조회하는 방법! (2) | 2022.01.13 |
| 파이썬 컴프리헨션-딕셔너리(dictionary) for&if문까지 한 줄로 작성! (0) | 2022.01.12 |
| 파이썬 컴프리헨션 문법, for문과 if문 한 줄로 리스트 코딩하기 (0) | 2022.01.12 |
| 파이썬 패키지 설치 오류, 깃허브(Github)를 이용해서 해결하기! (0) | 2022.01.12 |



