데이터 분석을 하기 위해 꼭 거쳐야 하는 과정 중의 하나는 EDA입니다. 저는 데이터 분석은 데이터를 확인하기 위해 지루하게 많은 반복작업을 거치는 과정이라고 생각합니다. 이러한 과정을 최대한 빠르고 효율적으로 하기 위해 도와주는 여러 툴들이 있는데요. 파이썬 판다스 데이터프레임에도 EDA 작업을 쉽게 할 수 있도록 도와주는 패키지가 있습니다. 오늘은 sweetviz 패키지에 대해서 알아보겠습니다.
sweetviz란?
sweetviz는 데이터 프레임에 대해 자동으로 보고서를 만들어주는 패키지입니다. 크게 analyze와 compare함수로 이루어져 있습니다. (compare_infra함수도 있지만, 데이터프레임을 compare함수로 대체가 가능합니다.)
analyze는 하나의 데이터셋을 비교하는 것이고, compare는 2개의 데이터셋을 서로 비교하는 것입니다. 하나의 데이터프레임에서 비교하고자 하는 칼럼이 있다면, 2개의 데이터셋으로 나눠서 비교할 수도 있습니다.
sweetviz 설치방법
sweetviz는 'pip install sweetviz' 명령으로 쉽게 설치가 가능합니다. 하지만, 의존된 패키지가 많아 인터넷이 연결되지 않은 곳에서는 설치가 쉽지 않습니다. 관련된 패키지의 용량이 크기 때문에, 와이파이 환경에서 설치하시는 것을 추천드립니다.
sweetviz 사용방법
사용하시기 전에 먼저 데이터 타입을 맞춰 주세요. sweetviz는 칼럼 데이터 타입에 따라, 다른 형태의 보고서를 만들어줍니다. 그래서 보고서를 생성하기 전에 데이터 타입을 맞춰주는 것이 좋습니다.
부동산 데이터를 수집하여 sweetviz로 보고서를 만들어 보았습니다. 부동산 데이터를 수집하는 방법은 다음에 다뤄보겠습니다. 사용한 데이터는 2020년 6월 구로구 아파트 매매 거래 데이터입니다.
데이터 타입을 맞추고 analyze함수를 실행했습니다.
df["전용면적"]=df["전용면적"].astype(float)
df["층"]=df["층"].astype(int)
df["건축년도"]=df["건축년도"].astype(int)
my_report=sweetviz.analyze(df)
my_report.show_html()
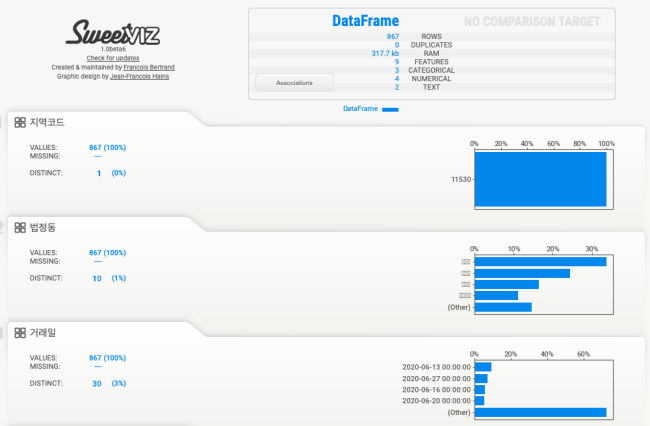
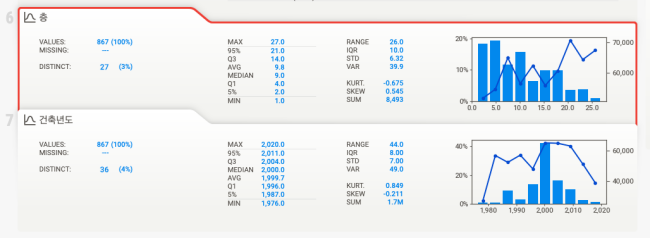
feat_cfg 파라미터로 거래일은 분석에서 생략하고, 전용면적은 문자열로 간주하고 분석하도록 옵션을 넣어보았습니다. target_feat에 숫자형이나 불리언 데이터 타입 변수를 넣을 수 있습니다. 변수를 넣으면, 아래와 같이 해당 변수의 값이나 분포를 추가로 확인할 수 있습니다.
my_report=sweetviz.analyze(df,
feat_cfg = sweetviz.FeatureConfig(skip="거래일", force_text=["전용면적"]),
target_feat="거래금액")
my_report.show_html()
comparte함수를 이용하면, 두 데이터를 비교할 수 있습니다. 신도림동과 구로동으로 나눠서 데이터를 비교해 보았습니다.
df_gr=dict(list(df.groupby("법정동")))
my_report=sweetviz.compare([df_gr["구로동"],"guro"], [df_gr["신도림동"],"sindorim"],
feat_cfg = sweetviz.FeatureConfig(skip="거래일"),
target_feat="거래금액")
my_report.show_html()

더 자세한 사용방법은 sweetviz 깃허브 페이지를 참조하기 바랍니다. sweetviz는 데이터를 빠르게 훑어보기에 좋은 툴입니다. 각 변수별로 분포와 그래프를 그려주기 때문에, 귀찮게 코딩할 일이 많이 줄어듭니다. 다만, 외국에서 개발된 패키지이다 보니 일부 그래프에서 한글이 깨져서 보입니다. 아쉽지만 영어로 이용하던가, 패키지의 폰트를 수정해줘야 합니다.
오늘은 이렇게 파이썬 데이터 분석, EDA를 도와주는 패키지인 sweetviz에 대해 알아보았습니다. 갈수록 데이터를 분석하고 시각화하는 일은 편리해지고 있습니다. 앞으로 더 좋은 도구들이 많이 나오길 바래봅니다.
pandas profiling 이용해보기
sweet viz와 유사한 패키지로 pandas profiling이 있습니다. 이 패키지는 Feature의 대표값 외에 상관관계도 확인해 볼 수 있습니다. pandas profiling에 대한 자세한 내용은 아래 포스팅을 참조하시기 바랍니다.
코랩(colab)에서 pandas_profiling 실행하는 방법은?!
pandas_profiling은 함수 하나로 손쉽게 데이터를 확인할 수 있어 유용하다. colab에는 이 패키지가 이미 설치돼 있다. 하지만 해당 패키지를 사용하려고 하니 에러가 발생한다. 오늘은
aplab.tistory.com
'데이터 > 데이터 분석' 카테고리의 다른 글
| 파이썬 애니메이션 차트 쉽게 만드는 방법은?! (0) | 2022.06.27 |
|---|---|
| 판다스 데이터프레임 칼럼 추가하는 2가지 방법과 장단점은?! (0) | 2022.06.17 |
| 한국수출입통계를 파이썬으로 bar chart 그리기 (0) | 2022.06.17 |
| yellow brick, ElbowVisualizer AttributeError?! (0) | 2022.05.25 |
| 코랩(colab)에서 pandas_profiling 실행하는 방법은?! (0) | 2022.04.30 |
| 파이썬 plotly 그래프 웹페이지, 블로그에 올리는 방법은?! (0) | 2022.04.28 |
| 파이썬 그래프 그리기, 동적으로 움직이는 그래프 그리는 방법은?! (0) | 2022.04.27 |
| 파이썬 대화형 그래프 쉽게 그리기, plotly express 이용 방법은?! (0) | 2022.04.26 |



